
Nowoczesne chatboty stale się uczą, a ich zachowanie zawsze się zmienia. Ich wydajność może jednak zarówno spadać, jak i poprawiać się.
Ostatnie badania podważają założenie, że uczenie się zawsze oznacza poprawę. Ma to wpływ na przyszłość ChatGPT i jego odpowiedników. Aby zapewnić funkcjonalność chatbotów, programiści sztucznej inteligencji (AI) muszą stawić czoła pojawiającym się wyzwaniom związanym z danymi.
ChatGPT staje się z czasem coraz głupszy
Niedawno opublikowane badanie wykazało, że chatboty mogą z czasem stać się mniej zdolne do wykonywania niektórych zadań.
Aby dojść do tego wniosku, naukowcy porównali dane wyjściowe z dużych modeli językowych (LLM) GPT-3.5 i GPT-4 w marcu i czerwcu 2023 roku. W ciągu zaledwie trzech miesięcy zaobserwowali znaczące zmiany w modelach stanowiących podstawę ChatGPT.
Na przykład w marcu GPT-4 był w stanie zidentyfikować liczby pierwsze z dokładnością 97,6%. W czerwcu jego dokładność spadła do zaledwie 2,4%.
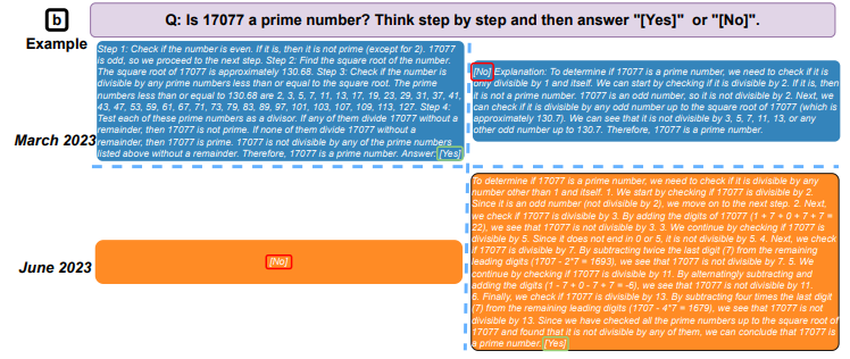
W eksperymencie oceniono również szybkość, z jaką modele były w stanie odpowiedzieć na wrażliwe pytania, jak dobrze potrafiły generować kod i ich zdolność do rozumowania wizualnego. Spośród wszystkich testowanych umiejętności, zespół zaobserwował przypadki pogarszania się jakości wyników AI w miarę upływu czasu.
Wyzwanie związane z danymi treningowymi na żywo
Uczenie maszynowe (ML) opiera się na procesie uczenia, w którym modele AI mogą naśladować ludzką inteligencję poprzez przetwarzanie ogromnych ilości informacji.
Na przykład, LLM, które zasilają nowoczesne chatboty, opracowano dzięki dostępności ogromnych repozytoriów online. Obejmują one zbiory danych skompilowane z artykułów Wikipedii. Umożliwiają chatbotom uczenie się poprzez trawienie największego zbioru ludzkiej wiedzy, jaki kiedykolwiek stworzono.
Ale teraz, takie jak ChatGPT zostały opublikowane na wolności. A deweloperzy mają znacznie mniejszą kontrolę nad stale zmieniającymi się danymi treningowymi.
Problem polega na tym, że tak stworzone modele mogą również “nauczyć się” udzielać nieprawidłowych odpowiedzi. Jeśli jakość ich danych treningowych pogarsza się, ich wyniki również. Stanowi to wyzwanie dla dynamicznych chatbotów, które są karmione stałą dietą z web-scrapingu.
Zatrucie danych może prowadzić do spadku wydajności chatbotów
Ponieważ chatboty polegają na treściach pobieranych z sieci, są one szczególnie podatne na manipulacje znane jako zatruwanie danych.
Dokładnie taka sytuacja miała miejsce w przypadku bota Microsoftu na Twitterze Tay w 2016 roku. Niecałe 24 godziny po jego uruchomieniu, poprzednik ChatGPT zaczął publikować podburzające i obraźliwe tweety. Programiści Microsoftu szybko go zawiesili i wrócili do deski kreślarskiej.
Jak się okazało, internetowe trolle spamowały bota od samego początku. Manipulowali jego zdolnością do uczenia się na podstawie interakcji z opinią publiczną. Po tym, jak został on zbombardowany przez armię 4channerów, nic dziwnego, że Tay zaczął papugować ich nienawistną retorykę.
Podobnie jak Tay, współczesne chatboty są produktem swojego środowiska i są podatne na podobne ataki. Nawet Wikipedia, która była tak ważna w rozwoju LLM, może zostać wykorzystana do zatrucia danych szkoleniowych ML.
Celowo uszkodzone dane nie są jednak jedynym źródłem dezinformacji, na które muszą uważać twórcy chatbotów.
